In Part 1 of my series on Timeseries Databases I have shown how to parse the DWD Open Data dataset. Part 2 showed how to write the data to InfluxDB and Part 3 explained how to fine tune TimescaleDB for efficiently writing data.
So once we got our Giga-, Peta- or Exa-bytes into a database one question comes up naturally:
What to do with the data?
And that's exactely the problem with so many Big Data projects.
Correlation and Causal Relation
While it's nowadays quite easy to store large amounts of data, actually making sense of it is a tough problem. And it's even harder to draw useful conclusions.
I am saying this, because many failed Data Mining experiments have taught me, that a high correlation in data does not imply a causal relation:
A high correlation between increased ice cream sales and murder rate, does not imply deadly ice cream.
(Hint: It's most probably the heat.)
Or ...
Just because a lot of people search for Flu-like symptoms, doesn't imply there's a flu epidemic.
(Hint: It's most probably winter.)
That brings me to my next point...
The Plan
My past articles on Big Data and Data Mining projects have been way too ambitious.
Sometimes I spent months reading papers, articles, blogs and studying code in GitHub repositories. And in the end I deleted most of the code in sheer frustration, because I didn't see any progress. Future articles will be much shorter and focus on smaller problems.
Instead of directly starting with data mining models and timeseries analysis I want to show how to visualize data first. Because for me working with data always starts with getting a feel for it.
I love making spatial data more accessible by creating choropleth maps:
A choropleth map (from Greek χῶρος "area/region" and πλῆθος "multitude") is a thematic map in which areas are shaded or patterned in proportion to the measurement of the statistical variable being displayed on the map, such as population density or per-capita income.
So this article will show you how to create choropleth maps using R, open data Shapefiles and TimescaleDB.
I want to show you how to create visualizations of the air temperature in Germany in 2017.
As usual all code to reproduce the article can be found in my GitHub repository at:
The Dataset
The DWD Open Data portal of the Deutscher Wetterdienst (DWD) gives access to the historical weather data in Germany. I decided to use all available historical air temperature data for Germany given in a 10 minute resolution (FTP Link).
What is a shapefile?
A shapefile is a format, which contains the map data with location, shape and attributes of geographic features.
The ArcGis documentation writes on the shapefile format:
A shapefile is an Esri vector data storage format for storing the location, shape, and attributes of geographic features. It is stored as a set of related files and contains one feature class. Shapefiles often contain large features with a lot of associated data and historically have been used in GIS desktop applications such as ArcMap. (Source)
The Esri Open Data Portal provides access to Open Data shapefiles, that can be used, re-used and redistributed freely.
For this post I am going to use the Zensus 2011 shapefile, which contains the federal states of Germany.
Generating Maps with R
Displaying the Shapefile
Once you have downloaded the shapefile, it can be rendered with R. I am going to use ggplot2 and the sf library in this example:
# Copyright (c) Philipp Wagner. All rights reserved.
# Licensed under the MIT license. See LICENSE file in the project root for full license information.
#install.packages("ggplot2")
#install.packages("sf")
library(ggplot2)
library(sf)
# Load the Germany Shapefile:
germany_shp <- st_read('D:\\github\\GermanWeatherDataExample\\GermanWeatherData\\TimescaleDB\\R\\shapes\\Zensus_2011_Bundeslaender.shp')
ggplot(germany_shp) +
geom_sf()
Which yields the following plot of Germany:

Reading the Features
When the shapefile is read by sf it outputs useful informations about the features included in the data:
Reading layer `Zensus_2011_Bundeslaender' from data source `D:\github\GermanWeatherDataExample\GermanWeatherData\TimescaleDB\R\shapes\Zensus_2011_Bundeslaender.shp' using driver `ESRI Shapefile'
Simple feature collection with 21 features and 13 fields
geometry type: MULTIPOLYGON
dimension: XY
bbox: xmin: 5.866479 ymin: 47.27011 xmax: 15.04182 ymax: 55.05838
epsg (SRID): 4326
proj4string: +proj=longlat +datum=WGS84 +no_defs
The following attributes are available in the data frame:
> names(germany_shp)
[1] "OBJECTID_1" "DES" "NAME" "EWZ" "EW_M" "EW_W"
[7] "EW_D" "EW_A" "ALTER_1" "ALTER_2" "ALTER_3" "ALTER_4"
[13] "ALTER_5" "geometry"
And what we need to display average temperatures is the name of the 16 federal states:
> germany_shp$NAME
[1] Bremen Rheinland-Pfalz Nordrhein-Westfalen
[4] Hamburg Schleswig-Holstein Baden-Württemberg
[7] Mecklenburg-Vorpommern Brandenburg Hessen
[10] Berlin Niedersachsen Baden-Württemberg
[13] Saarland Niedersachsen Bremen
[16] Sachsen-Anhalt Schleswig-Holstein Sachsen
[19] Mecklenburg-Vorpommern Bayern Thüringen
16 Levels: Baden-Württemberg Bayern Berlin Brandenburg Bremen Hamburg ... Thüringen
Plotting the Data
Distribution of the Weather Stations in Germany
Now the idea is the following: Use RPostgres to connect to TimescaleDB, read the SQL query from an external file and bind the start date to the query. At time of writing RPostgres only supports positional parameters for prepared statements:
SELECT identifier, name, start_date, end_date, station_height, state, latitude, longitude
FROM sample.station
WHERE end_date >= $1
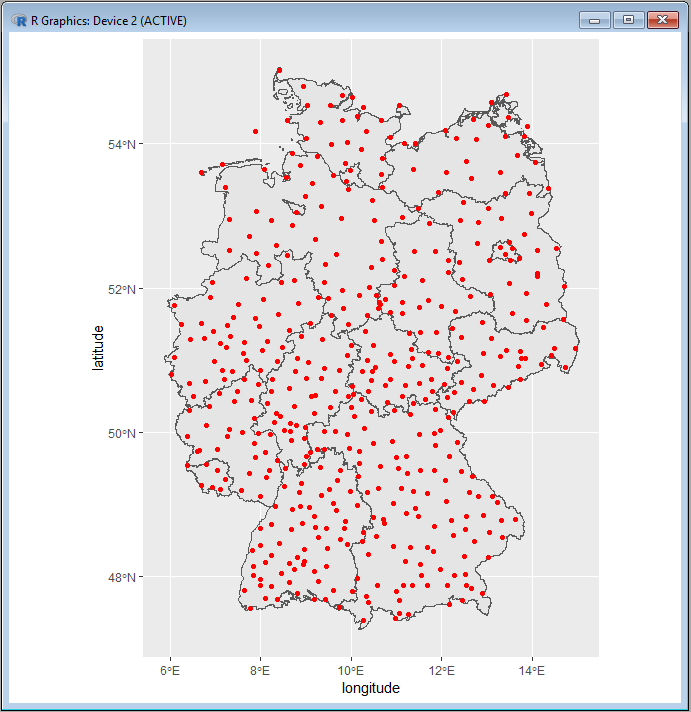
And the following R script is used to plot the position of German weather stations:
# Copyright (c) Philipp Wagner. All rights reserved.
# Licensed under the MIT license. See LICENSE file in the project root for full license information.
#install.packages("DBI")
#install.packages("RPostgres")
#install.packages("dplyr")
#install.packages("infuser")
#install.packages("magrittr")
#install.packages("viridis")
#install.packages("ggthemes")
#install.packages("ggplot2")
#install.packages("readr")
#install.packages("sp")
#install.packages("sf")
library(DBI)
library(dplyr)
library(infuser)
library(magrittr)
library(viridis)
library(ggthemes)
library(ggplot2)
library(readr)
library(sf)
# Connect to the Database:
connection <- dbConnect(RPostgres::Postgres(),
dbname = 'sampledb',
host = 'localhost', # i.e. 'ec2-54-83-201-96.compute-1.amazonaws.com'
port = 5432, # or any other port specified by your DBA
user = 'philipp',
password = 'test_pwd')
# Read the SQL Query from an external file and infuse the variables. Keeps the Script clean:
query <- read_file("D:\\github\\GermanWeatherDataExample\\GermanWeatherData\\TimescaleDB\\R\\stations\\query.sql")
# Query the Database:
stations <- dbGetQuery(connection, query, param = list('2017-01-01'))
# Close Postgres Connection:
dbDisconnect(connection)
# Load the Germany Shapefile:
germany_shp <- st_read('D:\\github\\GermanWeatherDataExample\\GermanWeatherData\\TimescaleDB\\R\\shapes\\Zensus_2011_Bundeslaender.shp')
ggplot(germany_shp) +
geom_sf() +
geom_point(data=stations, aes(x=longitude, y=latitude), color="red")
It shows, that every federal state has one weather station active in 2017:
Plotting the Average Temperature 2017
To plot the average templerature of the federal states in Germany, we first need to join the station table and
the weather_data table.
I am going to use the ANSI SQL avg operator to calculate the average temperature:
SELECT s.state "state", avg(w.air_temperature_at_2m) "avg_temp"
FROM sample.weather_data w
INNER JOIN sample.station s ON w.station_identifier = s.identifier
WHERE w.timestamp >= $1 AND w.timestamp < $2
GROUP BY "state"
By binding the positional parameters $1 and $2 of the SQL query, we can calculate the average temperature for a specific timespan.
So to calculate the average temperature for the year 2017, you just need to bind the dbGetQuery to 2017-01-01 and 2018-01-01:
# Copyright (c) Philipp Wagner. All rights reserved.
# Licensed under the MIT license. See LICENSE file in the project root for full license information.
#install.packages("DBI")
#instal.packages("RPostgres")
#install.packages("dplyr")
#install.packages("infuser")
#install.packages("magrittr")
#install.packages("viridis")
#install.packages("ggthemes")
#install.packages("ggplot2")
#install.packages("readr")
#install.packages("sp")
#install.packages("sf")
library(DBI)
library(dplyr)
library(infuser)
library(magrittr)
library(viridis)
library(ggthemes)
library(ggplot2)
library(readr)
library(sf)
# Connect to the Database:
connection <- dbConnect(RPostgres::Postgres(),
dbname = 'sampledb',
host = 'localhost', # i.e. 'ec2-54-83-201-96.compute-1.amazonaws.com'
port = 5432, # or any other port specified by your DBA
user = 'philipp',
password = 'test_pwd')
# Read the SQL Query from an external file and infuse the variables. Keeps the Script clean:
query <- read_file("D:\\github\\GermanWeatherDataExample\\GermanWeatherData\\TimescaleDB\\R\\maps\\query.sql")
# Query the Database:
temperatures <- dbGetQuery(connection, query, param = list('2017-01-01', '2018-01-01'))
# Close Postgres Connection:
dbDisconnect(connection)
# Load the Germany Shapefile:
germany_shp <- st_read('D:\\github\\GermanWeatherDataExample\\GermanWeatherData\\TimescaleDB\\R\\shapes\\Zensus_2011_Bundeslaender.shp')
# Fortify and Join with Temperatures:
germany_shp.df <- merge(fortify(germany_shp), as.data.frame(temperatures), by.x="NAME", by.y="state")
ggplot(germany_shp.df) +
geom_sf(aes(fill=avg_temp)) +
scale_fill_viridis()
The plot shows, that Bavaria had the lowest average temperature in Germany for 2017.
I am using the viridis color palette, because it is easier to read by those with color blindness and prints well in grey scale:

Average Temperature in July 2017
The above query and script enable us to easily plug in different values for drawing conclusions about the data.
To ask for the warmest federal states in July 2017 you just need to bind the dbGetQuery to 2017-07-01 and 2017-08-01:
# Query the Database:
temperatures <- dbGetQuery(connection, query, param = list('2017-07-01', '2017-08-01'))
And it shows, that tiny Saarland was the warmest federal state in July 2017:

Average Temperature in December 2017
To ask for the average temperature of the federal states in December 2017 you need to bind the dbGetQuery to 2017-12-01 and 2018-01-01:
# Query the Database:
temperatures <- dbGetQuery(connection, query, param = list('2017-12-01', '2018-01-01'))
And it shows, that Bavaria was the coldest federal state in December 2017:

Conclusion
And that's it for now!
I hope this article gives you a good start for using Shapefiles with R, and using RPostgres.