In my last post I have evaluated Neo4j on the Airline On Time Performance dataset. It would be a waste to not expand this example to the SQL Server 2017 Graph Database and see how it compares to Neo4j.
So in this article I want to show you how to efficiently insert the Airline On Time Performance Dataset into the SQL Server 2017 and
query the Graph Database using the SQL Server 2017 MATCH operation.
The source code for this article can be found in my GitHub repository at:
Table of contents
The Plan: Analyzing the Airline On Time Performance
The plan is to analyze the Airline On Time Performance dataset, which contains:
[...] on-time arrival data for non-stop domestic flights by major air carriers, and provides such additional items as departure and arrival delays, origin and destination airports, flight numbers, scheduled and actual departure and arrival times, cancelled or diverted flights, taxi-out and taxi-in times, air time, and non-stop distance.
The data spans a time range from October 1987 to present, and it contains more than 150 million rows of flight informations. It can be obtained as CSV files from the Bureau of Transportation Statistics Database, and requires you to download the data month by month.
More conveniently the Revolution Analytics dataset repository contains a ZIP File with the CSV data from 1987 to 2012.
Graph Databases
Microsoft has a perfect introduction to Graph Databases and their use cases :
What is a graph database
A graph database is a collection of nodes (or vertices) and edges (or relationships). A node represents an entity (for example, a person or an organization) and an edge represents a relationship between the two nodes that it connects (for example, likes or friends). Both nodes and edges may have properties associated with them. Here are some features that make a graph database unique:
- Edges or relationships are first class entities in a Graph Database and can have attributes or properties associated with them.
- A single edge can flexibly connect multiple nodes in a Graph Database.
- You can express pattern matching and multi-hop navigation queries easily.
- You can express transitive closure and polymorphic queries easily.
When to use a graph database
There is nothing a graph database can achieve, which cannot be achieved using a relational database. However, a graph database can make it easier to express certain kind of queries. Also, with specific optimizations, certain queries may perform better. Your decision to choose one over the other can be based on following factors:
- Your application has hierarchical data. The HierarchyID datatype can be used to implement hierarchies, but it has some limitations. For example, it does not allow you to store multiple parents for a node.
- Your application has complex many-to-many relationships; as application evolves, new relationships are added.
- You need to analyze interconnected data and relationships.
The Graph Database model
The Graph model is heavily based on the Neo4j Flight Database example by Nicole White:
(:Airport {airport_id, abbr, name})
(:City {name})
(:State {code, name})
(:Country {name, iso_code})
(:Carrier {code, description})
{:Flight {flight_number, year, month, day, })
(:Aircraft {tail_number})
(:Reason {code, description})
(:City)-[:IN_COUNTRY]→(:Country)
(:State)-[:IN_COUNTRY]→(:Country)
(:City)-[:IN_STATE]→(:State)
(:Airport)-[:IN_CITY]→(:City)
(:Flight)-[:ORIGIN {taxi_time, dep_delay} | :DESTINATION {taxi_time, arr_delay}]→(:Airport)
(:Flight)-[:CARRIER]→(:Carrier)
(:Flight)-[:CANCELLED_BY|:DELAYED_BY {duration}]→(:Reason)
(:Flight)-[:AIRCRAFT]→(:Aircraft)
You can find the original model of Nicole and a Python implementation over at:
She also posted a great Introduction To Cypher video on YouTube, which explains queries on the dataset in detail:
SQL-Side
The idea for Bulk Inserting the Nodes and Edges is quite simple, although I am not 100% sure if it is the best way.
Basically I am creating user-defined table types first (for example AirportType), which can then be used as a Table-Valued Parameter in a Stored Procedure (for example InsertAirports). The
Stored Procedure then inserts the Nodes to the table first and then builds the relationships upon. The downside with this approach is, that the Node Table (for example Airport) must contain all
necessary relationships and it leads to duplicate data.
The following listing shows the Stored Procedure InsertAirports, which is used to Batch insert a list of Airports. The procedure first inserts the City, State, Country and Airport nodes,
that are given in the Table-valued Parameter @Entities, and then the relationships inCity, inState and inCountry are populated:
USE $(dbname)
GO
IF OBJECT_ID(N'[InsertAirports]', N'P') IS NOT NULL
BEGIN
DROP PROCEDURE [InsertAirports]
END
GO
IF EXISTS (SELECT * FROM sys.types WHERE is_table_type = 1 AND name = 'AirportType')
BEGIN
DROP TYPE [AirportType]
END
CREATE TYPE [AirportType] AS TABLE (
[Identifier] [NVARCHAR](255),
[Abbr] [NVARCHAR](255),
[Name] [NVARCHAR](255),
[City] [NVARCHAR](255),
[StateCode] [NVARCHAR](255),
[StateName] [NVARCHAR](255),
[Country] [NVARCHAR](255),
[CountryIsoCode] [NVARCHAR](255)
);
GO
CREATE PROCEDURE [InsertAirports]
@Entities [AirportType] ReadOnly
AS
BEGIN
SET NOCOUNT ON;
-- Insert missing City Nodes:
INSERT INTO City
SELECT DISTINCT e.City
FROM @Entities e
WHERE NOT EXISTS (select * from City c where c.Name = e.City)
-- Insert missing State Nodes:
INSERT INTO State
SELECT DISTINCT e.StateCode, e.StateName
FROM @Entities e
WHERE NOT EXISTS (select * from State s where s.Name = e.StateName and s.Code = e.StateCode)
-- Insert missing Country Nodes:
INSERT INTO Country
SELECT DISTINCT e.Country, e.CountryIsoCode
FROM @Entities e
WHERE NOT EXISTS (select * from Country c where c.Name = e.Country)
-- Build the Temporary Staged Table for Inserts:
DECLARE @TemporaryAirportTable Table(
[AirportID] [INTEGER],
[NodeID] [NVARCHAR](1000),
[Airport] [NVARCHAR](255),
[Abbr] [NVARCHAR](255),
[Name] [NVARCHAR](255),
[City] [NVARCHAR](255),
[StateCode] [NVARCHAR](255),
[StateName] [NVARCHAR](255),
[Country] [NVARCHAR](255),
[CountryIsoCode] [NVARCHAR](255)
);
-- Insert into Temporary Table:
INSERT INTO Airport(Identifier, Abbr, Name, City, StateCode, StateName, Country, CountryIsoCode)
OUTPUT INSERTED.AirportID, INSERTED.$NODE_ID, INSERTED.Identifier, INSERTED.Abbr, INSERTED.Name, INSERTED.City, INSERTED.StateCode, INSERTED.StateName, INSERTED.Country, INSERTED.CountryIsoCode
INTO @TemporaryAirportTable
SELECT * FROM @Entities;
-- Build Relationships:
INSERT INTO inCity
SELECT airport.NodeID, (SELECT $NODE_ID FROM City where Name = airport.City)
FROM @TemporaryAirportTable airport;
INSERT INTO inState
SELECT airport.NodeID, (SELECT $NODE_ID FROM State where Code = airport.StateCode)
FROM @TemporaryAirportTable airport;
INSERT INTO inCountry
SELECT airport.NodeID, (SELECT $NODE_ID FROM Country where Name = airport.Country)
FROM @TemporaryAirportTable airport;
END
GO
.NET-Side
Project Structure
On a high-level the .NET-side of the Project looks like this:

AirlineOnTimePerformance
Converters- Contains Converters to convert between the CSV and SQL Data Representation.
CsvConverter- Converters for parsing the Flight data. The dataset requires us to convert from
1.00to a boolean for example.
- Converters for parsing the Flight data. The dataset requires us to convert from
Mapper- Defines the Mappings between the CSV File and the .NET model.
Model- Defines the .NET classes, that model the CSV data.
Parser- The Parsers required for reading the CSV data.
GraphClient- Includes the Clients to send data to the SQL Server 2017 in batches.
Extensions- Extensions methods on the
SqlDataRecordto simplify writing Nullable values.
- Extensions methods on the
Model- Defines the .NET classes, that match the user-defined SQL Server data types.
AirlineOnTimePerformance.ConsoleApp
The AirlineOnTimePerformance.ConsoleApp references the AirlineOnTimePerformance project. It uses the CSV Parsers to read the CSV data, converts
the flat CSV data model to the SQL data model and then inserts the entities using a BatchProcessor. Reactive Extensions are used for batching the
entities.
This leads to very succinct code like this:
private static void ProcessAirports(string csvFilePath)
{
// Construct the Batch Processor:
var processor = new AirportsBatchProcessor(ConnectionString);
// Create the Converter:
var converter = new AirportConverter();
// Access to the List of Parsers:
Parsers
// Use the Airport Parser:
.AirportParser
// Read the File:
.ReadFromFile(csvFilePath, Encoding.UTF8)
// As an Observable:
.ToObservable()
// Batch in 80000 Entities / or wait 1 Second:
.Buffer(TimeSpan.FromSeconds(1), 80000)
// And subscribe to the Batch
.Subscribe(records =>
{
var validRecords = records
// Get the Valid Results:
.Where(x => x.IsValid)
// And get the populated Entities:
.Select(x => x.Result)
// Only use latest Airports:
.Where(x => x.AirportIsLatest)
// Convert into the Sql Data Model:
.Select(x => converter.Convert(x))
// Evaluate:
.ToList();
// Finally write them with the Batch Writer:
processor.Write(validRecords);
});
}
Evaluating the SQL Server 2017 Graph Database
In the following example I will recreate the Cypher Query to find out, the Percentage of Flights delayed by Weather per Airport. This can be easily expressed with the following SQL Query and using the same MATCH Statements as in the last article:
SET STATISTICS TIME ON
SET STATISTICS IO ON
SELECT Name, DelayedByWeather, Total, 100.0 * DelayedByWeather / Total as Percentage
FROM
(SELECT a.Name as Name,
(SELECT Count(*)
FROM Flight, Airport, Reason, origin, delayedBy
WHERE MATCH(Airport<-(origin)-Flight-(delayedBy)->Reason)
AND Reason.Code = 'B'
AND Airport.Name = a.Name) as DelayedByWeather,
(SELECT COUNT(*)
FROM Flight, Airport, origin
WHERE MATCH(Flight-(origin)->Airport)
AND Airport.Name = a.Name) as Total
FROM Airport a) as AirportStatistics
WHERE Total > 0
ORDER BY Percentage DESC
Results
The query results differ slightly from the Neo4j results, I will investigate it and later update this post:
Name DelayedByWeather Total Percentage --------------------------------- ---------------- ----------- --------------- Joplin Regional 16 375 4.266666666666 Watertown International 8 212 3.773584905660 Martha's Vineyard Airport 6 161 3.726708074534 Columbia Regional 49 1326 3.695324283559 Deadhorse Airport 9 254 3.543307086614 Central Nebraska Regional 15 424 3.537735849056 Garden City Regional 12 367 3.269754768392 Chicago O'Hare International 5176 164598 3.144631161982 Chippewa County International 8 273 2.930402930402 Aspen Pitkin County Sardy Field 130 4488 2.896613190730 Dallas/Fort Worth International 6283 230053 2.731109787744 Sitka Rocky Gutierrez 12 441 2.721088435374 Ford 18 679 2.650957290132
Performance
It takes only 531 Milliseconds to execute the Query:
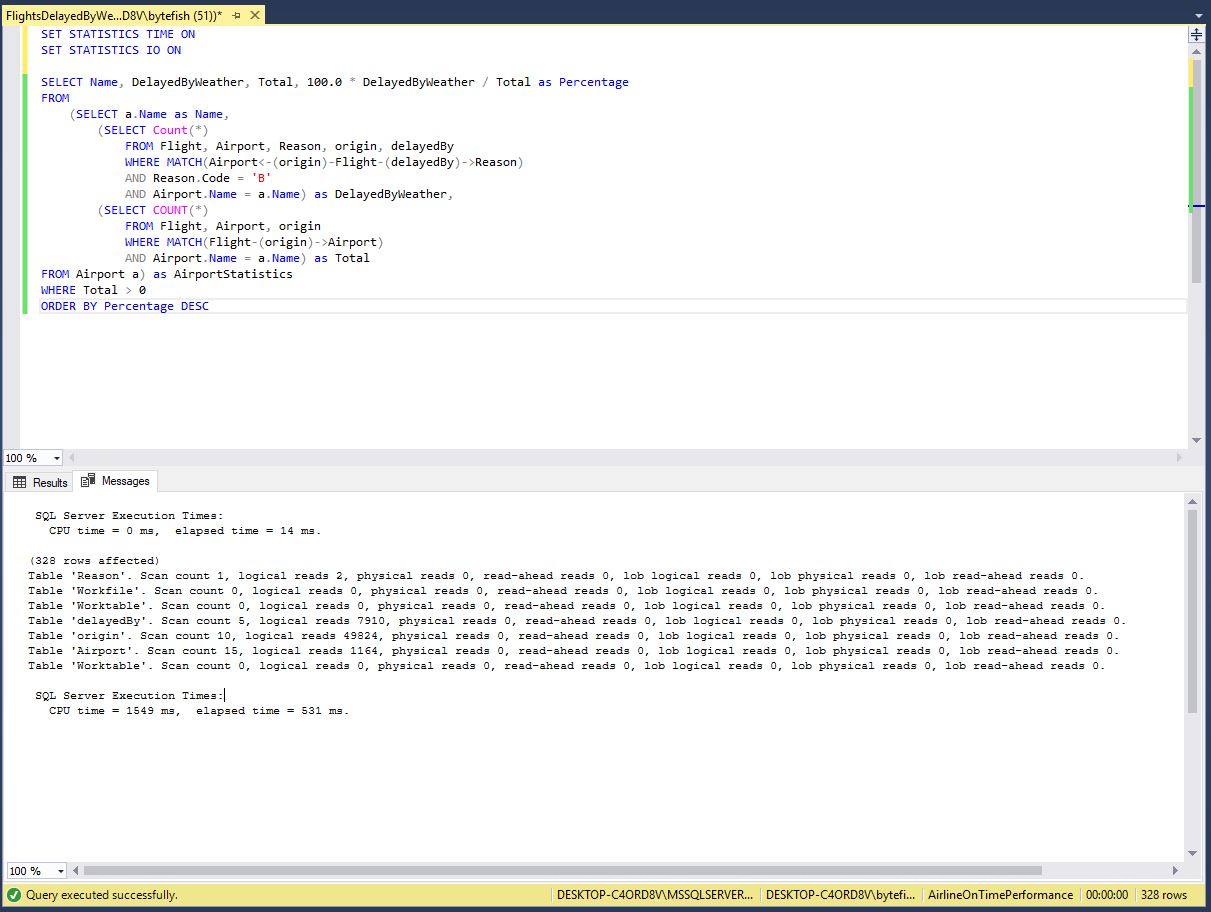
Here are the results in detail:
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 14 ms. (328 rows affected) Table 'Reason'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'delayedBy'. Scan count 5, logical reads 7910, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'origin'. Scan count 10, logical reads 49824, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Airport'. Scan count 15, logical reads 1164, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 1549 ms, elapsed time = 531 ms.
Conclusion
I am very impressed how fast the SQL Server 2017 Graph Database is! Querying for the Percentage of Flights delayed by Weather took 530 Milliseconds with the SQL Server 2017, while it took almost 30 Seconds with Neo4j. This makes me think, that something in my Neo4j Cypher Queries is horribly wrong. I am open for any feedback or help with the Neo4j queries!