In this article I am going to show you how to work with Elasticsearch in Java.
Source Code
You can find the full source code for the example in my git repository at:
What we are going to build
The idea is to store the hourly weather data of 1,600 U.S. locations in an Elasticsearch database and visualize it with Kibana.
The final result will visualize the average temperature in March 2015 on a tile map:
ElasticUtils
Working with the basic Elasticsearch Java API turned out to be quite time consuming. So I wrote the ElasticUtils library, which hides most of the complexity when working with Elasticsearch API. It greatly simplifies working with the Elasticsearch Mapping API and the Bulk Insert API.
ElasticUtils is released under terms of the MIT License:
You can add the following dependencies to your pom.xml to include ElasticUtils in your project:
<dependency>
<groupId>de.bytefish</groupId>
<artifactId>elasticutils</artifactId>
<version>0.3</version>
</dependency>
Setup
In the example I am using ElasticUtils for working with Elasticsearch and JTinyCsvParser to parse the CSV Weather data.
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.3.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.6.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.6.2</version>
</dependency>
<dependency>
<groupId>de.bytefish</groupId>
<artifactId>elasticutils</artifactId>
<version>0.3</version>
</dependency>
<dependency>
<groupId>de.bytefish</groupId>
<artifactId>jtinycsvparser</artifactId>
<version>1.1</version>
</dependency>
Dataset
The data is the Quality Controlled Local Climatological Data (QCLCD):
Quality Controlled Local Climatological Data (QCLCD) consist of hourly, daily, and monthly summaries for approximately 1,600 U.S. locations. Daily Summary forms are not available for all stations. Data are available beginning January 1, 2005 and continue to the present. Please note, there may be a 48-hour lag in the availability of the most recent data.
The data is available as CSV files at:
We are going to use the data from March 2015, which is located in the zipped file QCLCD201503.zip.
Reading the CSV data
Model
The first thing is to model the data we are interested in. The weather data is contained in the file 201503hourly.txt and the list
of available weather stations is given in the file 201503station.txt. The weather stations are identified by their WBAN number
(Weather-Bureau-Army-Navy).
LocalWeatherData
The local weather data in 201503hourly.txt has more than 30 columns, but we are only interested in the WBAN Identifier (Column 0),
Time of measurement (Columns 1, 2), Sky Condition (Column 4), Air Temperature (Column 12), Wind Speed (Column 24) and Pressure (Column 30).
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
package csv.model;
import java.time.LocalDate;
import java.time.LocalTime;
public class LocalWeatherData {
private String wban;
private LocalDate date;
private LocalTime time;
private String skyCondition;
private Float dryBulbCelsius;
private Float windSpeed;
private Float stationPressure;
public LocalWeatherData() {
}
// Getters and Setters ...
}
Station
The Station data has only 14 properties, the model is going to contain all properties.
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
package csv.model;
public class Station {
private String wban;
private String wmo;
private String callSign;
private String climateDivisionCode;
private String climateDivisionStateCode;
private String climateDivisionStationCode;
private String name;
private String state;
private String location;
private Float latitude;
private Float longitude;
private Integer groundHeight;
private Integer stationHeight;
private Integer barometer;
private Integer timeZone;
public Station() {
}
// Getters and Setters ...
}
Mapping
With JTinyCsvParser you have to define mapping between the column index and the property of the Java object.
This is done by implementing the abstract base class CsvMapping for the objects.
LocalWeatherDataMapper
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
package csv.mapping;
import csv.converter.IgnoreMissingValuesConverter;
import csv.model.LocalWeatherData;
import de.bytefish.jtinycsvparser.builder.IObjectCreator;
import de.bytefish.jtinycsvparser.mapping.CsvMapping;
import de.bytefish.jtinycsvparser.typeconverter.LocalDateConverter;
import de.bytefish.jtinycsvparser.typeconverter.LocalTimeConverter;
import java.time.LocalDate;
import java.time.LocalTime;
import java.time.format.DateTimeFormatter;
public class LocalWeatherDataMapper extends CsvMapping<LocalWeatherData>
{
public LocalWeatherDataMapper(IObjectCreator creator)
{
super(creator);
MapProperty(0, String.class, LocalWeatherData::setWban);
MapProperty(1, LocalDate.class, LocalWeatherData::setDate, new LocalDateConverter(DateTimeFormatter.ofPattern("yyyyMMdd")));
MapProperty(2, LocalTime.class, LocalWeatherData::setTime, new LocalTimeConverter(DateTimeFormatter.ofPattern("HHmm")));
MapProperty(4, String.class, LocalWeatherData::setSkyCondition);
MapProperty(12, Float.class, LocalWeatherData::setDryBulbCelsius, new IgnoreMissingValuesConverter("M"));
MapProperty(24, Float.class, LocalWeatherData::setWindSpeed, new IgnoreMissingValuesConverter("M"));
MapProperty(30, Float.class, LocalWeatherData::setStationPressure, new IgnoreMissingValuesConverter("M"));
}
}
StationMapper
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
package csv.mapping;
import csv.model.Station;
import de.bytefish.jtinycsvparser.builder.IObjectCreator;
import de.bytefish.jtinycsvparser.mapping.CsvMapping;
public class StationMapper extends CsvMapping<Station>
{
public StationMapper(IObjectCreator creator)
{
super(creator);
MapProperty(0, String.class, Station::setWban);
MapProperty(1, String.class, Station::setWmo);
MapProperty(2, String.class, Station::setCallSign);
MapProperty(3, String.class, Station::setClimateDivisionCode);
MapProperty(4, String.class, Station::setClimateDivisionStateCode);
MapProperty(5, String.class, Station::setClimateDivisionStationCode);
MapProperty(6, String.class, Station::setName);
MapProperty(7, String.class, Station::setState);
MapProperty(8, String.class, Station::setLocation);
MapProperty(9, Float.class, Station::setLatitude);
MapProperty(10, Float.class, Station::setLongitude);
MapProperty(11, Integer.class, Station::setGroundHeight);
MapProperty(12, Integer.class, Station::setStationHeight);
MapProperty(13, Integer.class, Station::setBarometer);
MapProperty(14, Integer.class, Station::setTimeZone);
}
}
IgnoreMissingValuesConverter
What is the IgnoreMissingValuesConverter?
If you carefully look at the CSV file you will see, that it has missing values. You don't want to discard the entire line,
just because of a missing value. Probably these values are optional? The missing values in the CSV files are identified by
an M (apparently for missing).
These values cannot be converted into a Float as defined in the mapping. That's why a custom converter
IgnoreMissingValuesConverter for the columns is implemented, which is done by deriving from a
ITypeConverter of the JTinyCsvParser library.
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
package csv.converter;
import de.bytefish.jtinycsvparser.typeconverter.ITypeConverter;
import utils.StringUtils;
import java.lang.reflect.Type;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class IgnoreMissingValuesConverter implements ITypeConverter<Float> {
private List<String> missingValueRepresentation;
public IgnoreMissingValuesConverter(String... missingValueRepresentation) {
this(Arrays.asList(missingValueRepresentation));
}
public IgnoreMissingValuesConverter(List<String> missingValueRepresentation) {
this.missingValueRepresentation = missingValueRepresentation;
}
@Override
public Float convert(final String s) {
if(StringUtils.isNullOrWhiteSpace(s)) {
return null;
}
boolean isMissingValue = missingValueRepresentation
.stream()
.anyMatch(x -> x.equals(s));
if(isMissingValue) {
return null;
}
return Float.parseFloat(s);
}
@Override
public Type getTargetType() {
return Float.class;
}
}
Parsers
The CSV file is parsed with a CsvParser from JTinyCsvParser. The CsvParser defines how to tokenize a line of CSV data
and how to instantiate the result objects. I am defining a class Parsers, that creates the CsvParser instances for the CSV
Station and the LocalWeatherData file.
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
package csv.parser;
import csv.mapping.LocalWeatherDataMapper;
import csv.mapping.StationMapper;
import csv.model.LocalWeatherData;
import csv.model.Station;
import de.bytefish.jtinycsvparser.CsvParser;
import de.bytefish.jtinycsvparser.CsvParserOptions;
import de.bytefish.jtinycsvparser.tokenizer.StringSplitTokenizer;
public class Parsers {
public static CsvParser<Station> StationParser() {
return new CsvParser<>(new CsvParserOptions(true, new StringSplitTokenizer("\\|", true)), new StationMapper(() -> new Station()));
}
public static CsvParser<LocalWeatherData> LocalWeatherDataParser()
{
return new CsvParser<>(new CsvParserOptions(true, new StringSplitTokenizer(",", true)), new LocalWeatherDataMapper(() -> new LocalWeatherData()));
}
}
Elasticsearch
If you are working with Elasticsearch the data needs to modeled different to a Relational Database. Instead of modelling relations between data in separate files, you need to store all data neccessary for a query in a document. The Elasticsearch documentation states on Handling Relationships:
Elasticsearch, like most NoSQL databases, treats the world as though it were flat. An index is a flat collection of independent documents. A single document should contain all of the information that is required to decide whether it matches a search request.
The Elasticsearch mindset is to denormalize the data as much as possible, because the inverted index is built over the documents and only this allows for efficient queries.
Model
We also need to define how the property names are serialized in the JSON document.
This is done by annotating a property with the Jackson JsonProperty annotation.
GeoLocation
If you want to define a property in your data as an Elasticsearch GeoPoint type, it needs to have at least the latitude or longitude with the property
names lat and lon.
This can easily be implemented with a custom class, that we call GeoLocation.
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
package elastic.model;
import com.fasterxml.jackson.annotation.JsonProperty;
public class GeoLocation {
@JsonProperty("lat")
public double lat;
@JsonProperty("lon")
public double lon;
public GeoLocation() {}
public GeoLocation(double lat, double lon) {
this.lat = lat;
this.lon = lon;
}
}
Station
The station has the same properties like the CSV file. It has the GPS informations of the station in a GeoLocation property.
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
package elastic.model;
import com.fasterxml.jackson.annotation.JsonProperty;
import org.elasticsearch.common.geo.GeoPoint;
public class Station {
@JsonProperty("wban")
public String wban;
@JsonProperty("name")
public String name;
@JsonProperty("state")
public String state;
@JsonProperty("location")
public String location;
@JsonProperty("coordinates")
public GeoLocation geoLocation;
}
LocalWeatherData
The LocalWeatherData contains the actual temperature, wind speed, pressure and so on. It also contains the Station, that generated the measurements.
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
package elastic.model;
import com.fasterxml.jackson.annotation.JsonProperty;
import java.util.Date;
public class LocalWeatherData {
@JsonProperty("station")
public Station station;
@JsonProperty("dateTime")
public Date dateTime;
@JsonProperty("temperature")
public Float temperature;
@JsonProperty("windSpeed")
public Float windSpeed;
@JsonProperty("stationPressure")
public Float stationPressure;
@JsonProperty("skyCondition")
public String skyCondition;
}
Mapping
Now the Elasticsearch mapping for the LocalWeatherData model needs to be defined.
This is done by implementing an BaseElasticSearchMapping from the ElasticUtils library.
LocalWeatherDataMapper
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
package elastic.mapping;
import de.bytefish.elasticutils.mapping.BaseElasticSearchMapping;
import org.elasticsearch.cluster.metadata.IndexMetaData;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.index.mapper.core.DateFieldMapper;
import org.elasticsearch.index.mapper.core.FloatFieldMapper;
import org.elasticsearch.index.mapper.core.StringFieldMapper;
import org.elasticsearch.index.mapper.geo.GeoPointFieldMapper;
import org.elasticsearch.index.mapper.object.ObjectMapper;
import org.elasticsearch.index.mapper.object.RootObjectMapper;
public class LocalWeatherDataMapper extends BaseElasticSearchMapping {
private static final String INDEX_TYPE = "document";
public LocalWeatherDataMapper() {
super(INDEX_TYPE, "1.0.0");
}
@Override
protected void configure(RootObjectMapper.Builder builder) {
builder
.add(new DateFieldMapper.Builder("dateTime"))
.add(new FloatFieldMapper.Builder("temperature"))
.add(new FloatFieldMapper.Builder("windSpeed"))
.add(new FloatFieldMapper.Builder("stationPressure"))
.add(new StringFieldMapper.Builder("skyCondition"))
.add(new ObjectMapper.Builder("station")
.add(new StringFieldMapper.Builder("wban"))
.add(new StringFieldMapper.Builder("name"))
.add(new StringFieldMapper.Builder("state"))
.add(new StringFieldMapper.Builder("location"))
.add(new GeoPointFieldMapper.Builder("coordinates")
.enableLatLon(true)
.enableGeoHash(false))
.nested(ObjectMapper.Nested.newNested(true, false)));
}
@Override
protected void configure(Settings.Builder builder) {
builder
.put(IndexMetaData.SETTING_VERSION_CREATED, 1)
.put(IndexMetaData.SETTING_CREATION_DATE, System.currentTimeMillis());
}
}
Converting between the CSV and Elasticsearch model
What's left is converting between the flat CSV data and the JSON document.
This is done by implementing a LocalWeatherDataConverter class, that takes the flat CSV Station and LocalWeatherData objects and builds the hierachial Elasticsearch model.
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
package converter;
import elastic.model.GeoLocation;
import elastic.model.Station;
import org.elasticsearch.common.geo.GeoPoint;
import utils.DateUtilities;
import java.sql.Date;
import java.time.ZoneId;
import java.time.ZoneOffset;
public class LocalWeatherDataConverter {
public static elastic.model.LocalWeatherData convert(csv.model.LocalWeatherData csvLocalWeatherData, csv.model.Station csvStation) {
elastic.model.LocalWeatherData elasticLocalWeatherData = new elastic.model.LocalWeatherData();
elasticLocalWeatherData.dateTime = DateUtilities.from(csvLocalWeatherData.getDate(), csvLocalWeatherData.getTime(), ZoneOffset.ofHours(csvStation.getTimeZone()));
elasticLocalWeatherData.skyCondition = csvLocalWeatherData.getSkyCondition();
elasticLocalWeatherData.stationPressure = csvLocalWeatherData.getStationPressure();
elasticLocalWeatherData.temperature = csvLocalWeatherData.getDryBulbCelsius();
elasticLocalWeatherData.windSpeed = csvLocalWeatherData.getWindSpeed();
// Convert the Station data:
elasticLocalWeatherData.station = convert(csvStation);
return elasticLocalWeatherData;
}
public static elastic.model.Station convert(csv.model.Station csvStation) {
elastic.model.Station elasticStation = new elastic.model.Station();
elasticStation.wban = csvStation.getWban();
elasticStation.name = csvStation.getName();
elasticStation.state = csvStation.getState();
elasticStation.location = csvStation.getLocation();
elasticStation.geoLocation = new GeoLocation(csvStation.getLatitude(), csvStation.getLongitude());
return elasticStation;
}
}
Integration Test
And finally it is time to connect the parts into an integration test.
You can see how to instantiate the Elasticsearch ElasticUtils mapping, how to configure the BulkProcessor and how to wrap the
original Elasticsearch Client in the ElasticUtils ElasticSearchClient client.
Then the Index is created, the mapping is put into Elasticsearch and the Stream of data is indexed.
The Stream of CSV data is created by using the CsvParser instances, and the flat CSV data is then converted into the Elasticsearch representation.
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
import converter.LocalWeatherDataConverter;
import csv.parser.Parsers;
import de.bytefish.elasticutils.client.ElasticSearchClient;
import de.bytefish.elasticutils.client.bulk.configuration.BulkProcessorConfiguration;
import de.bytefish.elasticutils.client.bulk.options.BulkProcessingOptions;
import de.bytefish.elasticutils.mapping.IElasticSearchMapping;
import de.bytefish.elasticutils.utils.ElasticSearchUtils;
import elastic.model.LocalWeatherData;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.junit.Ignore;
import org.junit.Test;
import java.net.InetAddress;
import java.nio.charset.StandardCharsets;
import java.nio.file.FileSystems;
import java.nio.file.Path;
import java.util.Map;
import java.util.stream.Collectors;
import java.util.stream.Stream;
@Ignore("Integration Test")
public class IntegrationTest {
@Test
public void bulkProcessingTest() throws Exception {
// Index to operate on:
String indexName = "weather_data";
// Describes how to build the Mapping:
IElasticSearchMapping mapping = new elastic.mapping.LocalWeatherDataMapper();
// Bulk Options for the Wrapped Client:
BulkProcessorConfiguration bulkConfiguration = new BulkProcessorConfiguration(BulkProcessingOptions.builder()
.setBulkActions(100)
.build());
// Create a new Client with default options:
try (TransportClient transportClient = TransportClient.builder().build()) {
transportClient.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
createIndex(transportClient, indexName);
createMapping(transportClient, indexName, mapping);
// Now wrap the Elastic client in our bulk processing client:
try (ElasticSearchClient<LocalWeatherData> client = new ElasticSearchClient<>(transportClient, indexName, mapping, bulkConfiguration)) {
// And now process the data stream:
try (Stream<elastic.model.LocalWeatherData> weatherDataStream = getLocalWeatherData()) {
client.index(weatherDataStream);
}
}
}
}
private void createIndex(Client client, String indexName) {
if(!ElasticSearchUtils.indexExist(client, indexName).isExists()) {
ElasticSearchUtils.createIndex(client, indexName);
}
}
private void createMapping(Client client, String indexName, IElasticSearchMapping mapping) {
if(ElasticSearchUtils.indexExist(client, indexName).isExists()) {
ElasticSearchUtils.putMapping(client, indexName, mapping);
}
}
private static Stream<elastic.model.LocalWeatherData> getLocalWeatherData() {
// Data to read from:
Path stationFilePath = FileSystems.getDefault().getPath("C:\\Users\\philipp\\Downloads\\csv", "201503station.txt");
Path weatherDataFilePath = FileSystems.getDefault().getPath("C:\\Users\\philipp\\Downloads\\csv", "201503hourly.txt");
try (Stream<csv.model.Station> stationStream = getStations(stationFilePath)) {
// Build a Map of Stations for faster Lookup, when parsing:
Map<String, csv.model.Station> stationMap = stationStream
.collect(Collectors.toMap(csv.model.Station::getWban, x -> x));
// Now read the LocalWeatherData from CSV:
return getLocalWeatherData(weatherDataFilePath)
.filter(x -> stationMap.containsKey(x.getWban()))
.map(x -> {
// Get the matching Station:
csv.model.Station station = stationMap.get(x.getWban());
// Convert to the Elastic Representation:
return LocalWeatherDataConverter.convert(x, station);
});
}
}
private static Stream<csv.model.Station> getStations(Path path) {
return Parsers.StationParser().readFromFile(path, StandardCharsets.US_ASCII)
.filter(x -> x.isValid())
.map(x -> x.getResult());
}
private static Stream<csv.model.LocalWeatherData> getLocalWeatherData(Path path) {
return Parsers.LocalWeatherDataParser().readFromFile(path, StandardCharsets.US_ASCII)
.filter(x -> x.isValid())
.map(x -> x.getResult());
}
}
Visualizing the Data with Kibana
Kibana is a front-end to visualize the indexed data stored in an Elasticsearch database. It's possible to create various graphs (line charts, pie charts, tilemaps, ...) and combine the created visualizations into custom dashboards. Kibana also updates the dashboard as soon as new data is indexed in Elasticsearch, which is a really cool feature to show your customers.
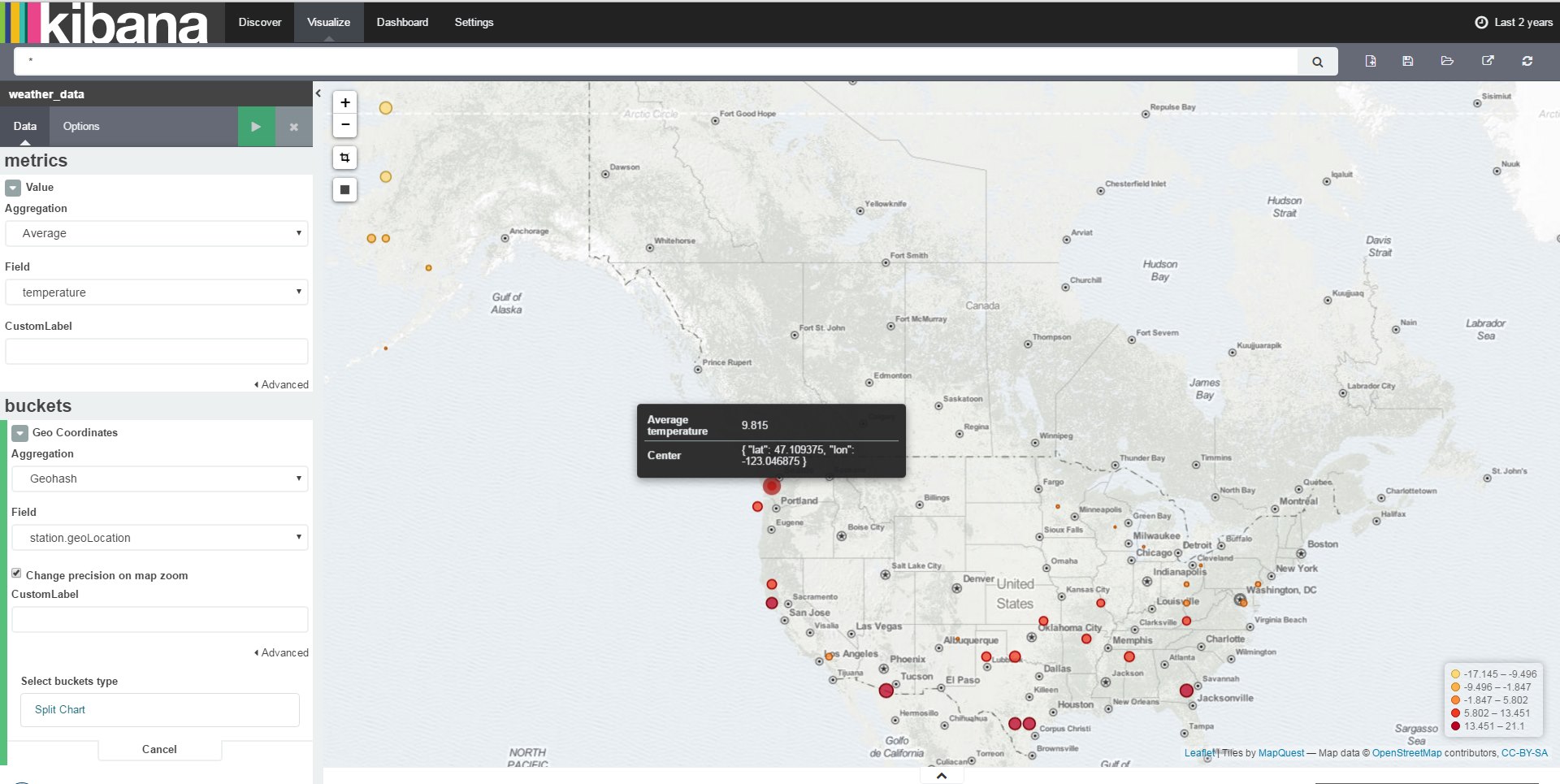
In the following example I want to show how to create a Tile Map, that shows the Average temperature of March 2015.
Starting Kibana
After starting the Kibana you can access the front-end using a browser and visiting:
http://localhost:5601
1. Configure the Index Pattern
In the example application the created index was called weather_data. To visualize this index with Kibana, an index pattern must be configured.
You are going to the Settings tab and set the Index name or pattern to weather_data:

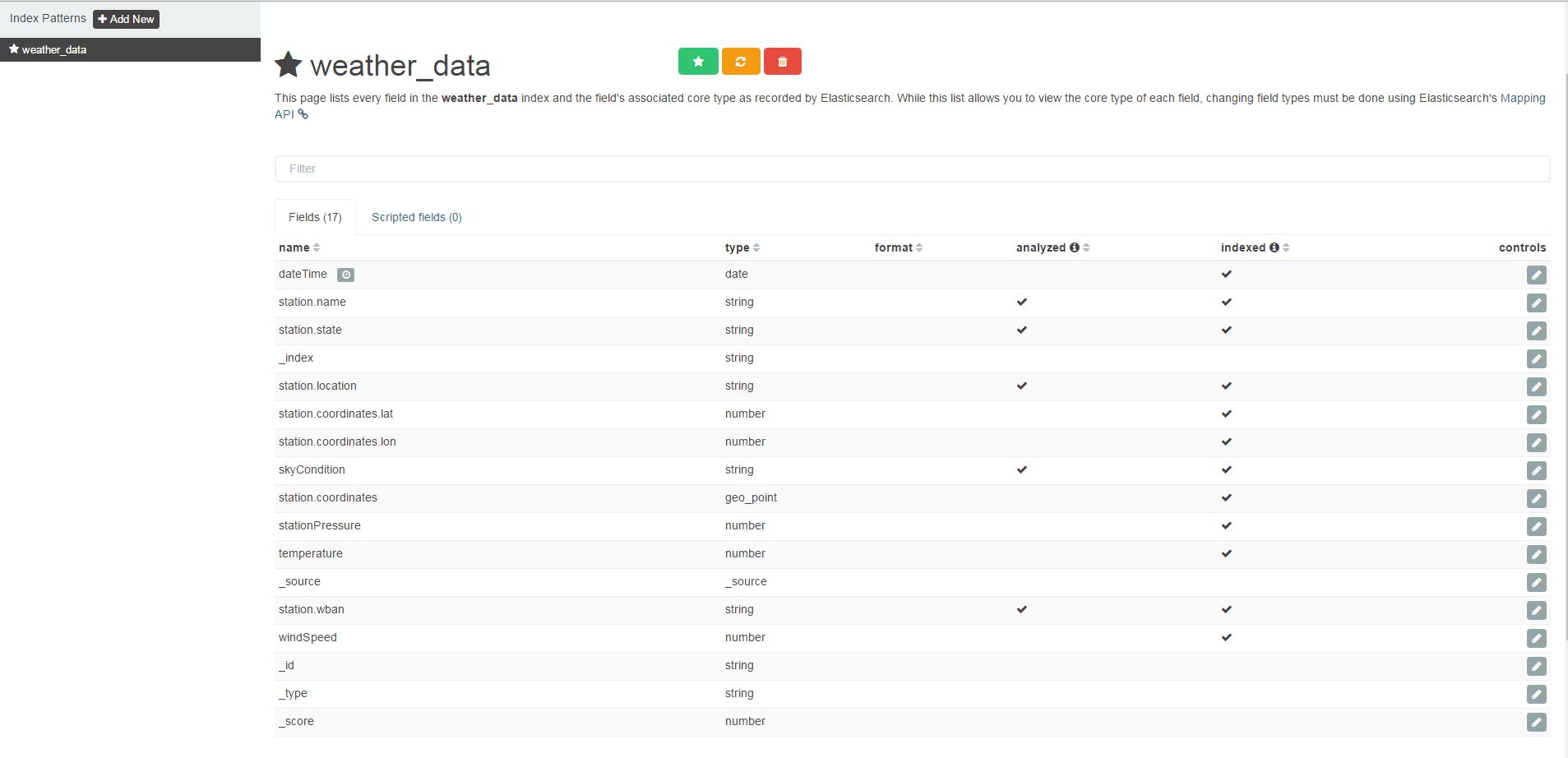
2. Inspecting the Index Pattern
3. Create the Tile Map Visualization

4. Create the Visualization from a New Search
We haven't stored any searches over the index yet, so the tile map needs to be created from a new search:

5. Choosing the Geocordinates for the Tile Map markers
The indexed data contains the GPS coordinates of each station. We are going to choose these GPS positions as Geo Coordinates:

6. Inspecting the Geo Coordinates
There is only one Geo Position property in the index. Kibana should automatically choose this property, but you should inspect to see if the correct values has been determined:

7. Adding the Average Temperature Value
We want to visualize the Average Temperature, add a new value. Aggregation must be set to Average and Field must be set to temperature:

8. Adjusting the Interval
You don't see values yet. This is because of the search interval Kibana defaults to. The indexed data is from March 2015, but Kibana visualize only the latest 15 Minutes by default. You need to set the interval to a larger time interval, by adjusting it in the upper right corner of the Kibana front-end.
I have highlighted it with a red marker in the following screenshot:

Final Visualization
And now you can enjoy the final visualization of the Average temperature in March 2015:
Conclusion
Getting started with Elasticsearch in Java was harder, compared to the .NET version. It should be much easier to create a mapping programmatically with the official Elasticsearch client. On the other hand, I found the source code of Elasticsearch highly readable and it wasn't hard to implement a simpler client by myself.
Kibana is a nice front-end for quickly visualizing data, especially the Tile Map is an amazing feature.
I hope you had fun reading this article, and it gave you some insight on how to work with Elasticsearch in Java.